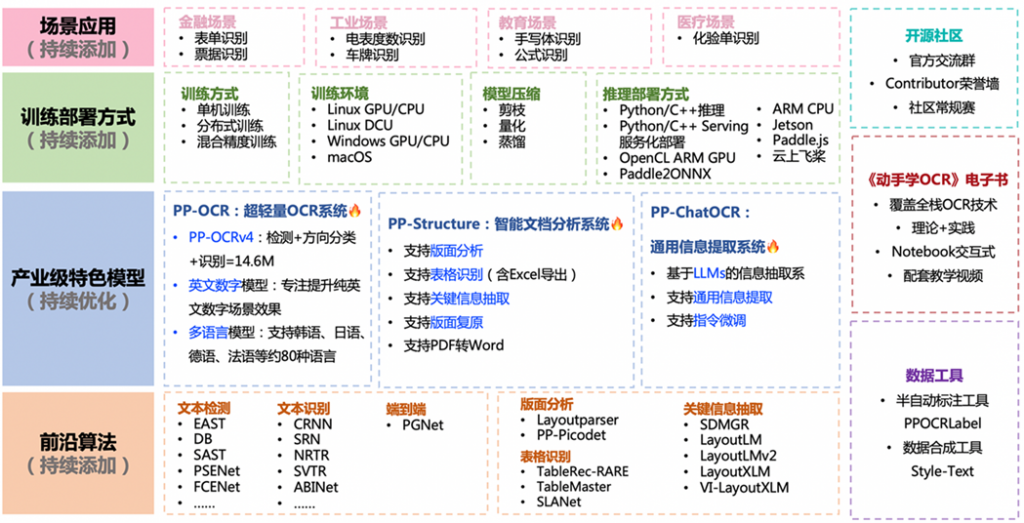
- 1:简介
- 2:环境安装
- 2.1:1. 创建python环境
- 2.2:2. 安装paddlepaddle
- 2.3:3. 安装paddleOCR whl包
- 3:快速使用
- 3.1:1. 命令行方式使用
- 3.2:2.python脚本方式使用
- 4:其他特性
- 5:与OmniAI对比
简介
PaddleOCR是由百度研发的一个基于深度学习的开源OCR(Optical Character Recognition,光学字符识别)工具库。
官方文档地址:https://paddlepaddle.github.io/PaddleOCR/main/index.html
开源项目地址:https://github.com/PaddlePaddle/PaddleOCR
环境安装
1. 创建python环境
使用conda管理python环境。
创建环境 conda create -n paddleOCR python=3.10 激活paddleOCR环境 conda activate paddleOCR
2. 安装paddlepaddle
如果电脑上安装了CUDA 11,可以安装GPU版本
pip install paddlepaddle-gpu
如果电脑使用CPU进行推理,安装CPU版本
pip install paddlepaddle
paddle根据版本、操作系统、安装方式、GPU芯片类型还提供了多种安装命令,请参照飞桨官网(https://www.paddlepaddle.org.cn/install/quick)安装文档中的说明进行操作。
3. 安装paddleOCR whl包
pip install paddleocr
快速使用
1. 命令行方式使用
PaddleOCR提供了一系列测试图片,点击这里(https://paddleocr.bj.bcebos.com/dygraph_v2.1/ppocr_img.zip)下载并解压,然后在终端中切换到相应目录。
如果不使用提供的测试图片,可以将下方--image_dir参数替换为相应的测试图片路径。
1.1 中英文模型
- 检测+方向分类器+识别全流程:--use_angle_cls true设置使用方向分类器识别180度旋转文字,--use_gpu false设置不使用GPU
paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu false
结果是一个list,每个item包含了文本框,文字和识别置信度
[28.0, 37.0], [302.0, 39.0], [302.0, 72.0], [27.0, 70.0, ('纯臻营养护发素', 0.9658738374710083)]
......
此外,paddleocr也支持输入pdf文件,并且可以通过指定参数page_num来控制推理前面几页,默认为0,表示推理所有页。
paddleocr --image_dir ./xxx.pdf --use_angle_cls true --use_gpu false --page_num 2
- 单独使用检测(不使用识别模块):设置 --rec为false
paddleocr --image_dir ./imgs/11.jpg --rec false
结果是一个list,每个item只包含文本框
27.0, 459.0], [136.0, 459.0], [136.0, 479.0], [27.0, 479.0
28.0, 429.0], [372.0, 429.0], [372.0, 445.0], [28.0, 445.0
......
- 单独使用识别(只提取文字,不检测文字所在位置):设置--det为false
paddleocr --image_dir ./imgs_words/ch/word_1.jpg --det false
结果是一个list,每个item只包含识别结果和识别置信度
['韩国小馆', 0.994467]
1.2 多语言模型
PaddleOCR目前支持80个语种,可以通过修改--lang参数进行切换,对于英文模型,指定--lang=en。
paddleocr --image_dir ./imgs_en/254.jpg --lang=en
结果是一个list,每个item包含了文本框,文字和识别置信度
[67.0, 51.0], [327.0, 46.0], [327.0, 74.0], [68.0, 80.0, ('PHOCAPITAL', 0.9944712519645691)]
[72.0, 92.0], [453.0, 84.0], [454.0, 114.0], [73.0, 122.0, ('107 State Street', 0.9744491577148438)]
[69.0, 135.0], [501.0, 125.0], [501.0, 156.0], [70.0, 165.0, ('Montpelier Vermont', 0.9357033967971802)]
......
2.python脚本方式使用
通过Python脚本使用PaddleOCR whl包,whl包会自动下载ppocr轻量级模型作为默认模型。
- 检测+方向分类器+识别全流程
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
结果是一个list,每个item包含了文本框,文字和识别置信度
- 使用滑动窗口进行检测和识别
要使用滑动窗口进行光学字符识别(OCR),可以使用以下代码片段:
from paddleocr import PaddleOCR
from PIL import Image, ImageDraw, ImageFont
# 初始化OCR引擎
ocr = PaddleOCR(use_angle_cls=True, lang="en")
img_path = "./very_large_image.jpg"
slice = {'horizontal_stride': 300, 'vertical_stride': 500, 'merge_x_thres': 50, 'merge_y_thres': 35}
results = ocr.ocr(img_path, cls=True, slice=slice)
# 加载图像
image = Image.open(img_path).convert("RGB")
draw = ImageDraw.Draw(image)
font = ImageFont.truetype("./doc/fonts/simfang.ttf", size=20) # 根据需要调整大小
# 处理并绘制结果
for res in results:
for line in res:
box = [tuple(point) for point in line[0]]
# 找出边界框
box = [(min(point[0] for point in box), min(point[1] for point in box)),
(max(point[0] for point in box), max(point[1] for point in box))]
txt = line[1][0]
draw.rectangle(box, outline="red", width=2) # 绘制矩形
draw.text((box[0][0], box[0][1] - 25), txt, fill="blue", font=font) # 在矩形上方绘制文本
# 保存结果
image.save("result.jpg")
此示例初始化了启用角度分类的PaddleOCR实例,并将语言设置为英语。然后调用ocr方法,并使用多个参数来自定义检测和识别过程,包括处理图像切片的slice参数。
其他特性
- 在此基础上可以对模型进行微调,增加对特定类型图像的识别准确率。
- 相对于视觉大语言模型,paddle的模型参数很小。
- 官方提供了低代码平台,方便开发部署。
- 提供多种算法。
- 除了OCR还提供很多实用的功能,如:版面分析、表格识别、版面恢复、关键信息提取等。
与OmniAI对比
OmniAI是基于视觉大语言模型的OCR工具